Example1: To find the links of title in a webpage list:
The target website is http://www.yeeyi.com/bbs/forum-304-1.html
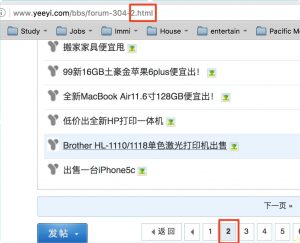
1. Analyse on the url:
if we poke around the page 1, page 2, or others , we can find the rule:
the common part is http://www.yeeyi.com/bbs/forum-304-x.html, the x represent the page number.
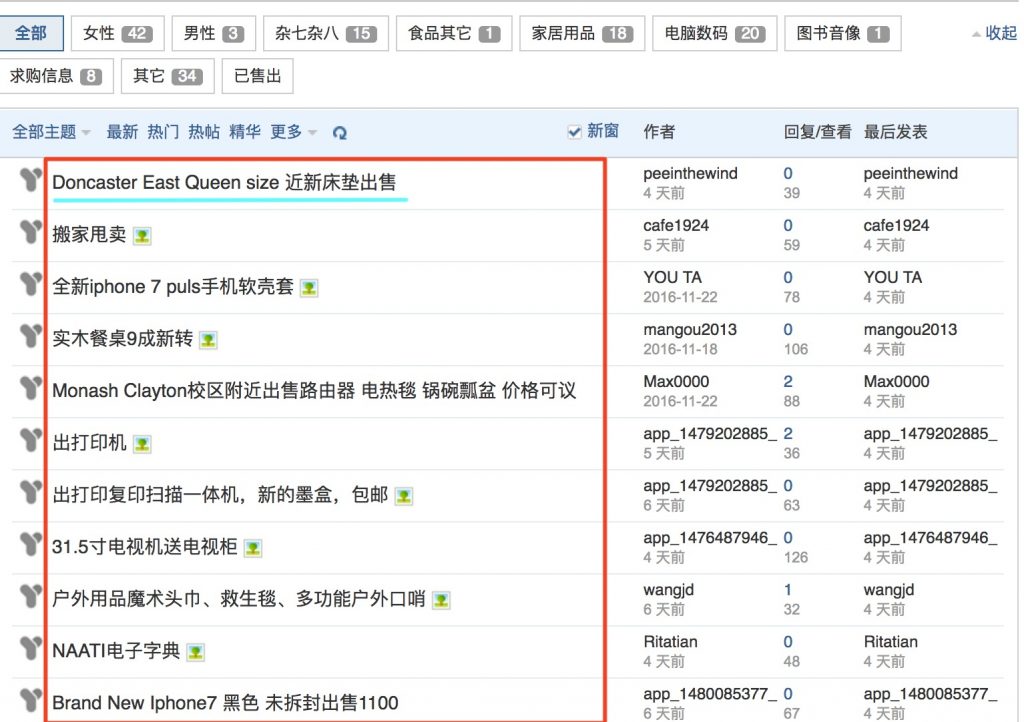
2. Analyse on the element we need
We only want to craw the links of the titles, so if we click here, we get into the page.
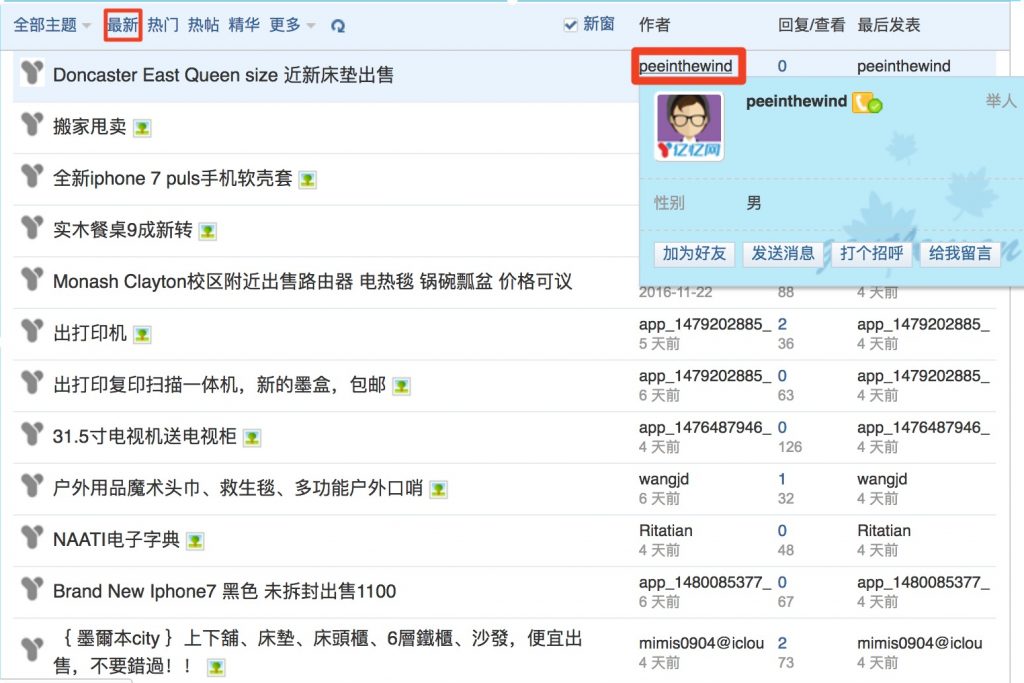
At the same Time, there are a lot of other links, such as the author name:
So we need to check the source code of the webpage and find the unique tag for the target data, right click in a blank area, click “inspect element” or similar name according to your web browser. Usually web developer use class or id to identify elements in webpage.
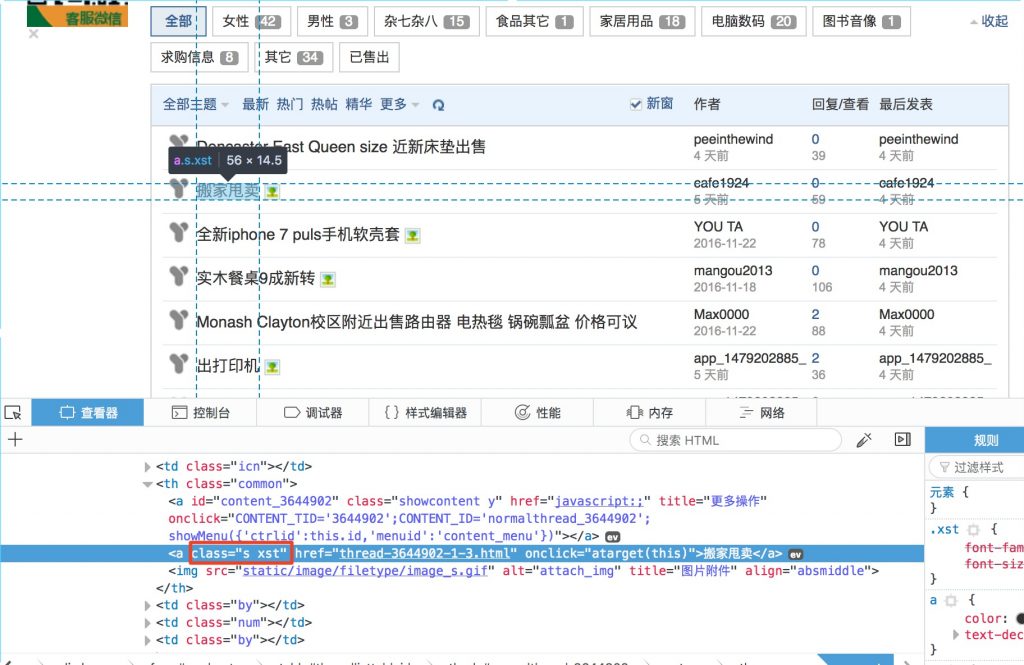
Now we need to create a loop to craw from page 1 to the desired page (max page).
import requests
from bs4 import BeautifulSoup
def trade_spider(max_pages):
page=1
while page <= max_pages:
url1="http://www.yeeyi.com/bbs/forum-304-"+ str(page)+".html"
print("the page is %s" % url1)
source_code=requests.get(url1)
plain_text=source_code.text
soup=BeautifulSoup(plain_text)
for link in soup.findAll('a', {'class':'s xst'}):
href1=link.get('href')
title=link.string
print(title +":")
print(href1)
page += 1 #the page number will increment after each loop.
Call the crawling function:
trade_spider(3) #we craw from page 1 to page 3
If you want to add the title of the post in front of the link, replace the last 3 lines with following codes:
title=link.string print(title +":") print(href1) print()
If we call it again
trade_spider(3)
The result :
二手储物架壁橱格子柜出售:
http://www.yeeyi.com/bbs/thread-3641546-1-3.html
出售一台外星人x51打包benq显示器送键盘:
http://www.yeeyi.com/bbs/thread-3636075-1-3.html
………………..
EXAMPLE2: TO FIND THE phone numbers IN A WEBPAGE:
Sometimes we also want to get the phone number from a page.
Target page: http://www.yeeyi.com/bbs/forum.php?mod=viewthread&tid=3645129
In this page, we can find the class of <td>( table data) in every row is same, the title column is “tit”, and the value column is “con” or “con2”. So how we can extract only the phone number out of this table?
After some analysis, I notice that the content of the td before the phone number td is always “电话:”, so I can find the td “电话:” first, then extract the content of the next sibling td ( phone number).
Step1, We begin by reading in the source code for a given web page and creating a Beautiful Soup object with the BeautifulSoup function.
import requests
from bs4 import BeautifulSoup
def get_single_item_data(item_url):
source_code2=requests.get(item_url)
plain_text=source_code2.text
soup=BeautifulSoup(plain_text,"lxml")
content=soup.prettify() # get the web page code.
Step2, find the table data of “电话:”
The related part of the html code is :
<tr> <td class="tit"> 电话: # this is the text we are looking for, the phone number will be the next one. </td> <td class="con2"> 12345678 # this is the text we actually needed. </td> <td class="tit"> 微信: </td> <td class="con"> </td> </tr>
In the first example, we find the content according to the class which was easy to find the desired content, this time we are going to find the content between the open and closing tag. So we will use the property “contents“, then use the “nextSibling” go get the content we need.
for hit in soup.findAll(attrs={'class':'tit'}): # Use for loop to read all the class tit if hit.contents[0]=="电话:": # Check if the content of the previous tag matches ”电话“ phone=hit.nextSibling # If it matched, the next sibling tag content will be the phone number. print(phone.contents[0].strip())url="http://www.yeeyi.com/bbs/forum.php?mod=viewthread&tid=3645129" get_single_item_data(url)
Step3. Correct the error
By now, if we test the code, we can get the phone number, but there will be some error code:
if hit.contents[0]=="电话:": IndexError: list index out of range
This is because we forgot to test if the hit is empty or not, and if think further the hit.nextSibling should also be tested before we print the result. we can add a line like following to correct this:
if hit is not None and len(hit) > 0
for hit in soup.findAll(attrs={'class':'tit'}):
if hit is not None and len(hit) > 0:
if hit.contents[0]=="电话:":
phone=hit.nextSibling
If phone is not None and Len(phone) > 0
print(phone.contents[0].strip())
Example 3 : combine example 1 and 2, we can call function
All we need is to call the function “get_single_item_data()” after print the title and url:
...
print(href1)
get_single_item_data(url)
page+=1
...
and pass the url crawled from example 1. so the program will crawl all the url and title, contact numbers according to the max page you needed.